


柯洁与AlphaGo对弈
这个结果在很多人意料之中,其中也包括柯洁。
第一场赛后发布会上,柯洁直言AI的进步速度太快了,并且每一次都是巨大的进步。这也是为什么他在大赛前夕发布微博称,此次将是他与人工智能的最后三盘对决。
柯洁心中已经清晰的知道,人类已经无法战胜AlphaGo。他形容AlphaGo越来越像“围棋上帝”,想赢它只能去找一些BUG,但目前,他还没看到AlphaGo的任何弱点。
这里引用搜狗CEO王小川在知乎上发布的内容,再向大家科普一下AlphaGo。
去年的AlphaGo 混合了三种算法,即蒙特卡洛树搜索+监督学习+增强学习。
其中蒙特卡洛树搜索是一种优化过的暴力计算;监督学习,是通过学习3000万部人类棋谱,对六段以上职业棋手走棋规律进行模仿,也是AlphaGo获得突破性进展的关键算法;而增强学习作为辅助,是两台AlphaGo从自我对战中学习如何下棋。
每当获取棋局信息时,AlphaGo 会根据策略网络探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。在分配的搜索时间结束时,模拟过程中被系统最频繁考察的位置将成为AlphaGo 的最终选择。
简单来说,AlphaGo下棋依靠的是概率,而概率的得出则依靠前期学习。而这次与柯洁对战的AlphaGo相较于去年,已经判若两人。
最初的AlphaGo主要依靠监督学习,即学习对象几乎全部来自人类棋手,而新版的AlphaGo则强化了增强学习,主要对机器自我对弈产生的棋局进行学习。
难怪柯洁会觉得,去年AlphaGo的下法还很接近人类,但今年自己对战时,AlphaGo已变得更加不合乎“常理”,下了很多人类棋手不可能下的棋子。
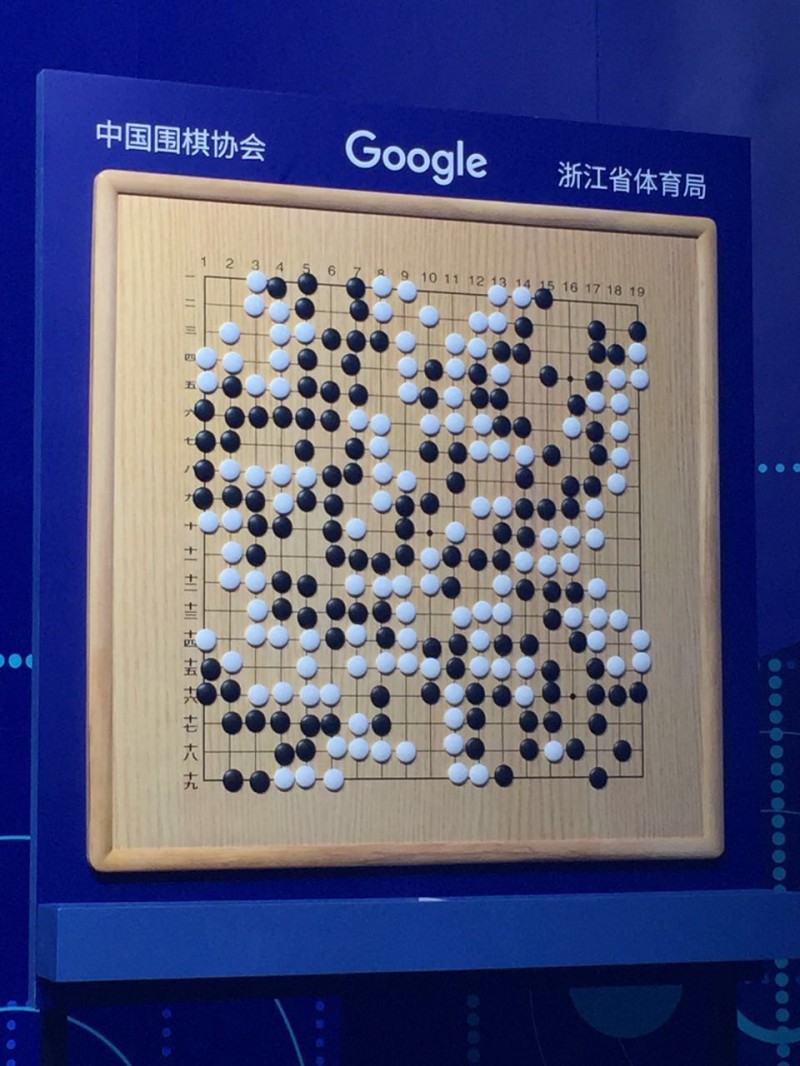
第一局结果
DeepMind创始人、AlphaGo之父Demis Hassabis证实了这一点,他说与柯洁对战的AlphaGo更多的是根据自身学习,对人类数据的依赖性越来越小。
除了开始脱离人类数据,更让人类望尘莫及的是其恐怖的进步速度。我们常说要“取长补短”,AlphaGo则可以把这个过程加快成百上千倍。
取长方面暂不多说,AlphaGo的研发团队一直在找它的缺口。去年输给李世石之后,他们回去马上改善了AlphaGo的知识缺口,并且投入更多精力去改进算法,让AlphaGo变得更强。
这次的AlphaGo在算法上就强大了很多。去年,AlphaGo还是通过分布式的计算机来运作,而今年只用了一个单一的机器。所以,柯洁非但没有让AlphaGo的CPU因为飞速运转而发热,相反,今天的AlphaGo的计算能力比去年要小10倍。
从比赛用时上来看,柯洁几乎是AlphaGo的两倍。双方第一场比赛共耗时4小时17分37秒,其中柯洁用时2小时46分43秒,AlphaGo用时1小时30分54秒。
学的又多又快,人类棋手确实很难看到胜算。柯洁也看到了这一点,但他为什么还要应战。
这也是普通网友最关心的问题了,柯洁的输赢到底是否需要将其上升到“人类尊严”这种高度?答案肯定是不能。
围棋如同所有竞技赛事一样,柯洁也是专业的运动员。对于运动员来说,胜败乃兵家常事,面对实力悬殊很大的对手,任何人都很难取胜。
现在柯洁面对的就是这样一个对手。所以对于比赛接下来的关注点不该是柯洁能否胜一局,而是AlphaGo所代表AI技术将为人类带来什么。
目前来看,AlphaGo已经颠覆了传统的围棋。柯洁在比赛中也尝试了一些“非常规”下法,他认为AlphaGo已经改变了自己很多最初的看法,现在觉得比赛中没有什么棋是不能下的。
Demis Hassabis在赛前的致辞中说道,围棋的样式变化繁多,可能再过一万年,人类也无法穷尽围棋的打法。
而AlphaGo可以作为一个工具,通过它去帮助人类对于围棋的理解,让伟大的棋手去发现围棋更多的奥妙。
这确实是一种很奇妙的感觉。当你认为一件几乎是唯一的事情,突然有了另外一种可能,这就像哥伦布发现新大陆后,给未来开启了一扇新的大门。
柯洁说活到现在,最大的荣幸是和AlphaGo进行了对战,很感谢能有这样的对手。他从AlphaGo身上获得了很多比赛的快乐,这种快乐来自于竞技,而非结果。
比赛结束以后,柯洁更希望把AlphaGo当做帮助自己提升棋艺的工具。在人与机器之间,他选择跟人类下棋,他笑着说,“我跟人类比赛的胜率还是可以的。”






 01月07日 18:14
01月07日 18:14